How I Beat Prediction Markets with LLMs
I got into Machine Learning in the 2010s through Kaggle competitions, but I’ve always been intrigued by prediction markets and their more free-form questions. Most important business questions look more like prediction market questions because they lack 1000s of previous training examples that fit nicely as structured data.
So I’m experimenting with a system that combines LLM’s flexibility with conventional ML rigor to answer questions from the Metaculus and Kalshi prediction markets. The results have been impressive, outperforming average human judgment in prediction markets that recently seemed impossible to address with AI.
This post describes the results, the key challenges, and the tips you’d need to build your own superhuman forecasting system with LLMs.
Why Prediction Markets Are Different
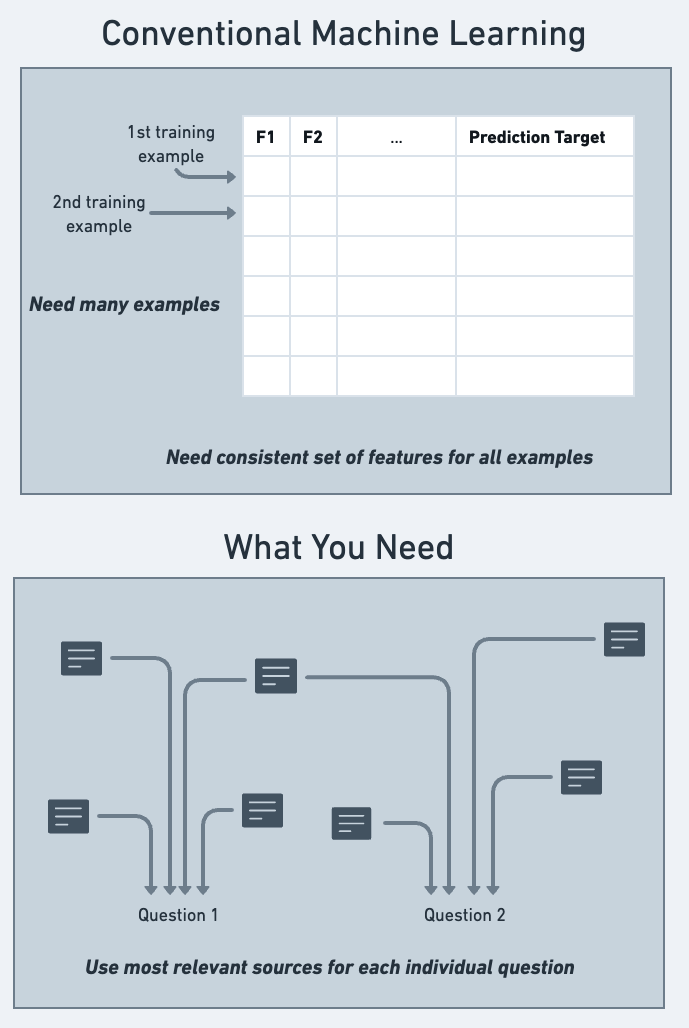
Imagine a beverage manufacturer deciding whether to invest in new machinery. They’ll need to forecast whether potential changes in international trade tariffs will affect sales. But how will tariffs actually change?
Xgboost-style ML won’t help because we have too few instances of trade negotiations between newly elected leaders to build a a training dataset. And the best practical insight today may be in sources (e.g. a niche Substack newsletter) that didn’t exist in older historical data .
We need a way to answer one-off questions using the best available information, even when it isn’t in the form of repeated observations with fixed features.
Simply asking an LLM how likely an event is without any structure leads to poor forecasting results. Instead, I landed on prompts that prescribe the best practices from Philip Tetlock’s book “Superforecasters.” He describes the keys among people who succeed in prediction markets:
-
Fermi estimation or back-of-the-envelope models to conduct concrete numerical analysis even without any single perfect data source
-
Breaking complex problems into smaller components that can be analyzed individually and recombined
-
Research to find historical analogs to estimate “base rate” probabilities for some primitives in your mental model
-
Constantly seeking out new information to revise/update the model for each question
-
Counterfactual thinking to repeatedly understand a model’s implications and revise it
An LLM with access to tools like internet search effectively imitated these techniques. Using ML-style validation, I verified that the predictions outperform average human performance in a dataset of Metaculus questions.
| Accuracy | AUC | Log Loss | |
|---|---|---|---|
| LLM with tools | 0.67 | 0.71 | 0.62 |
| Human | 0.62 | 0.66 | 0.75 |
| LLM without tools | 0.59 | 0.63 | 0.77 |
Model Validation
I conducted validation with 695 binary-outcome questions downloaded from Metaculus.
Example questions include:
- Will a major cyberattack, virus, worm, etc. that uses LLMs in some important way occur before Sept 30, 2024?
- Will the Canadian Dollars to U.S. Dollar Spot Exchange Rate exceed 1.3600 on Friday September 20, 2024, according to FRED?
- Will diplomatic expulsions or recalls take place between the Philippines and China before August 1, 2024?
- Drake vs Kendrick Lamar: will either artist release another diss track in May 2024?
My favorite thing about good validation setups is that you can test changes in a minute or two. So I ran many tests of alternative setups, measuring predictive performance on this dataset after each change.
Validation with LLM-based prediction is more complex than conventional ML validation. Specifically, LLMs introduce a new source of target leakage.
A current LLMs can easily “predict” events from 2022 because the event is described in documents in the LLMs training data. When a model is used prospectively to predict new events, it won’t have that advantage… so it won’t replicate the validation scores. To make validation useful, validation questions must come from after the LLMs training data cutoff.
But the LLM also lacks important context for questions asked long after the LLM’s training window.
Say you want to predict whether Bitcoin will finish this month at a price above $100,000. The current price is extremely valuable information. But a model trained on data up to Jan 1, 2024 won’t have any context beyond that date. Without current knowledge, it will perform poorly.
In theory, you could give the model relevant data in the prompt. But we want models to do extensive research beyond the manual effort we put into a prompt. So we instead give the model tools (like news search or Wikipedia search) to do this research itself.
I test the models by having them answer questions based on the information available when a prediction questions is added to Metaculus. If we want to know what a model would predict on some date X, the tools must show the state of information available on exactly that date. When we make predictions on new events in the future, we let these functions retrieve current data without time limitations.
This requires care with tool choice. Tools like News API and Wikipedia let you set the publication dates an LLM can access. Tools that combine all available information and expose only the current state of knowledge (e.g. Tavily) can’t be used with this backtesting and validation.
My New Livelihood?
After iterating with prompts and tools using validation, and I began testing the system live.
I wanted to test with money rather than internet points, which rules out some very well run prediction markets like Metaculus and Manifold Markets. Meanwhile US law prohibits most prediction markets for money (e.g. Polymarket). Kalshi is the exception where I can legally place monetary stakes in a prediciton market.
I initially placed bets 11 bets on Kalshi that closed within two weeks of the bet.
I fill in the actual results here when they are ready.
In any case, I won’t use Kalshi as a primary income source over the long term. Here’s a simplified model of the economics to explain why:
Say you place 10 bets on Kalshi at 50/50 odds. For simplicy, assume each bid is $1 (I’ll scale this up after showing the basic mechanics). You beat the odds by winning 6 out of the 10 bets.
You are paid back $2 for each of the wins, yielding $12. That is 20% more than you initially staked. To earn $10,000 in expected, you’d each bet to stake $50,000. Each bet would need to be $5,000. Most Kalshi questions lack the liquidity to make these bets without dramatically hurting your betting odds.
In practice, earnings as a fraction of bets is much worse due to Kalshi fees which cut into earnings.
Where to Now?
I expected it to be hard to make an LLM forecast better than human prediction market participants. So I’m excited to push further and see how accurate these systems can get. I’ll keep working on it. I also think these systems will help businesses work smarter by forecasting upcoming events.
Since I won’t make a living through prediction markets, I can also freely share more of my insights on this blog. Follow me here or hit me up on social media if you want to learn more.